A hands-on dive into Apache Kafka to build a scalable and fault-tolerant persistence layer.
With its most recent release, Apache Kafka introduced a couple of interesting changes, not least of which is Log Compaction, in this article we will walk through a simplistic use case which takes advantage of it.
Log compaction: the five minute introduction.
I won’t extensively detail what log compaction is, since it’s been thoroughly described. I encourage readers not familiar with the concept or Apache Kafka in general to go through these articles which give a great overview of the system and its capabilities:
- http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
- http://blog.confluent.io/2015/02/25/stream-data-platform-1/
- http://blog.confluent.io/2015/02/25/stream-data-platform-2/
In this article we will explore how to build a simple materialized view from the contents of a compacted kafka log. A working version of the approach described here can be found at https://github.com/pyr/kmodel and may be used as a companion while reading the article.
If you’re interested in materialized views, I warmly recommend looking into Apache Samza and this Introductory blog-post by Martin Kleppmann.
Overall architecture
For the purpose of this experiment, we will consider a very simple job board application. The application relies on a single entity type: a job description, and either does per-key access or retrieves the whole set of keys.
Our application will perform every read from the materialized view in redis, while all mutation operation will be logged to kafka.
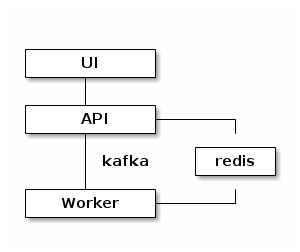
In this scenario all components may be horizontally scaled. Additionaly the materialized view can be fully recreated at any time, since the log compaction ensures that at least the last state of all live keys are present in the log. This means that by starting a read from the head of the log, a consistent state can be recreated.
Exposed API
A mere four rest routes are necessary to implement this service:
GET /api/job: retrieve all jobs and their description.POST /api/job: insert a new job description.PUT /api/job/:id: modify an existing job description.DELETE /api/job/:id: remove a job description.
We can map this REST functionality to a clojure protocol - the rough equivalent of an interface in OOP languages - with a mere 4 signatures:
(defprotocol JobDB
"Our persistence protocol."
(add! [this payload] [this id payload] "Upsert entry, optionally creating a key")
(del! [this id] "Remove entry.")
(all [this] "Retrieve all entries."))
Assuming this protocol is implemented, writing the HTTP API is relatively straightforward when leveraging tools such as compojure in clojure:
(defn api-routes
"Secure, Type-safe, User-input-validating, Versioned and Multi-format API.
(just kidding)"
[db]
(->
(routes
(GET "/api/job" [] (response (all db)))
(POST "/api/job" req (response (add! db (:body req))))
(PUT "/api/job/:id" [id :as req] (response (add! db id (:body req))))
(DELETE "/api/job/:id" [id] (response (del! db id)))
(GET "/" [] (redirect "/index.html"))
(resources "/")
(not-found "<html><h2>404</h2></html>"))
(json/wrap-json-body {:keywords? true})
(json/wrap-json-response)))
I will not describe the client-side javascript code used to interact with the API in this article, it is a very basic AngularJS application.
Persistence layer
Were we to use redis exclusively, the operation would be quite straightforward, we would rely on a redis set to contain the set of all known keys. Each corresponding key would contain a serialized job description.
In terms of operations, this would mean:
- Retrieval, would involve a
SMEMBERSof thejobskey, then mapping over the result to issue aGET. - Insertions and updates could be merge into a single “Upsert”
operation which would
SETa key and would then add the key to the known set through aSADDcommand. - Deletions would remove the key from the known set through a
SREMcommand and would thenDELthe corresponding key.
Let’s look at an example sequence of events
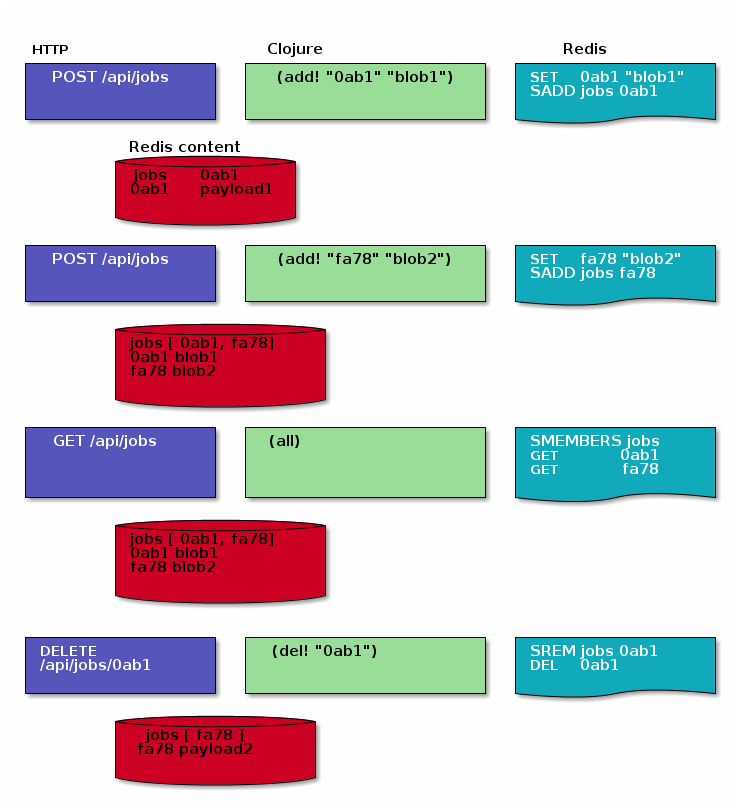
As it turns out, it is not much more work when going through Apache Kafka.
-
Persistence interaction in the API
In the client, retrieval happens as described above. This example code is in the context of the implementation - or as clojure would have it reification - of the above protocol.
(all [this] ;; step 1. Fetch all keys from set (let [members (redis/smembers "jobs")] ;; step 4. Merge into a map (reduce merge {} ;; step 2. Iterate on all keys (for [key members] ;; step 3. Create a tuple [key, (deserialized payload)] [key (-> key redis/get edn/read-string)]))))The rest of the operations emit records on kafka:
(add! [this id payload] (.send producer (record "job" id payload))) (add! [this payload] (add! this (random-id!) payload)) (del! [this id] (.send producer (record "job" id nil))))))Note how deletions just produce a record for the given key with a nil payload. This approach produces what is called a tombstone in distributed storage systems. It will tell kafka that prior entries can be discarded but will keep it for a configurable amount of time to ensure coordination across consumers.
-
Consuming persistence events
On the consumer side, the approach is as described above
(defmulti materialize! :op) (defmethod materialize! :del [payload] (r/srem "jobs" (:key payload)) (r/del (:key payload))) (defmethod materialize! :set [payload] (r/set (:key payload) (pr-str (:msg payload))) (r/sadd "jobs" (:key payload))) (doseq [payload (messages-in-stream {:topic "jobs"})] (let [op (if (nil? (:msg payload) :del :set))] (materialize! (assoc payload :op op))))
Scaling strategy and view updates
Where things start to get interesting, is that with this approach, the following becomes possible:
- The API component is fully stateless and can be scaled horizontally. This is not much of a break-through and is usually the case.
- The redis layer can use a consistent hash to shard across several instances and better use memory. While this is feasible in a more typical scenario, re-sharding induces a lot of complex manual handling. With the log approach, re-sharding only involves re-reading the log.
- The consumer layer may be horizontally scaled as well
Additionally, since a consistent history of events is available in the log, adding views which generate new entities or ways to look-up data now only involve adapating the consumer and re-reading from the head of the log.
Going beyond
I hope this gives a good overview of the compaction mechanism. I used redis in this example, but of course, materialized views may be created on any storage backends. But in some cases even this is unneeded! Since consumers register themselves in zookeeper, they could directly expose a query interface and let clients contact them directly.